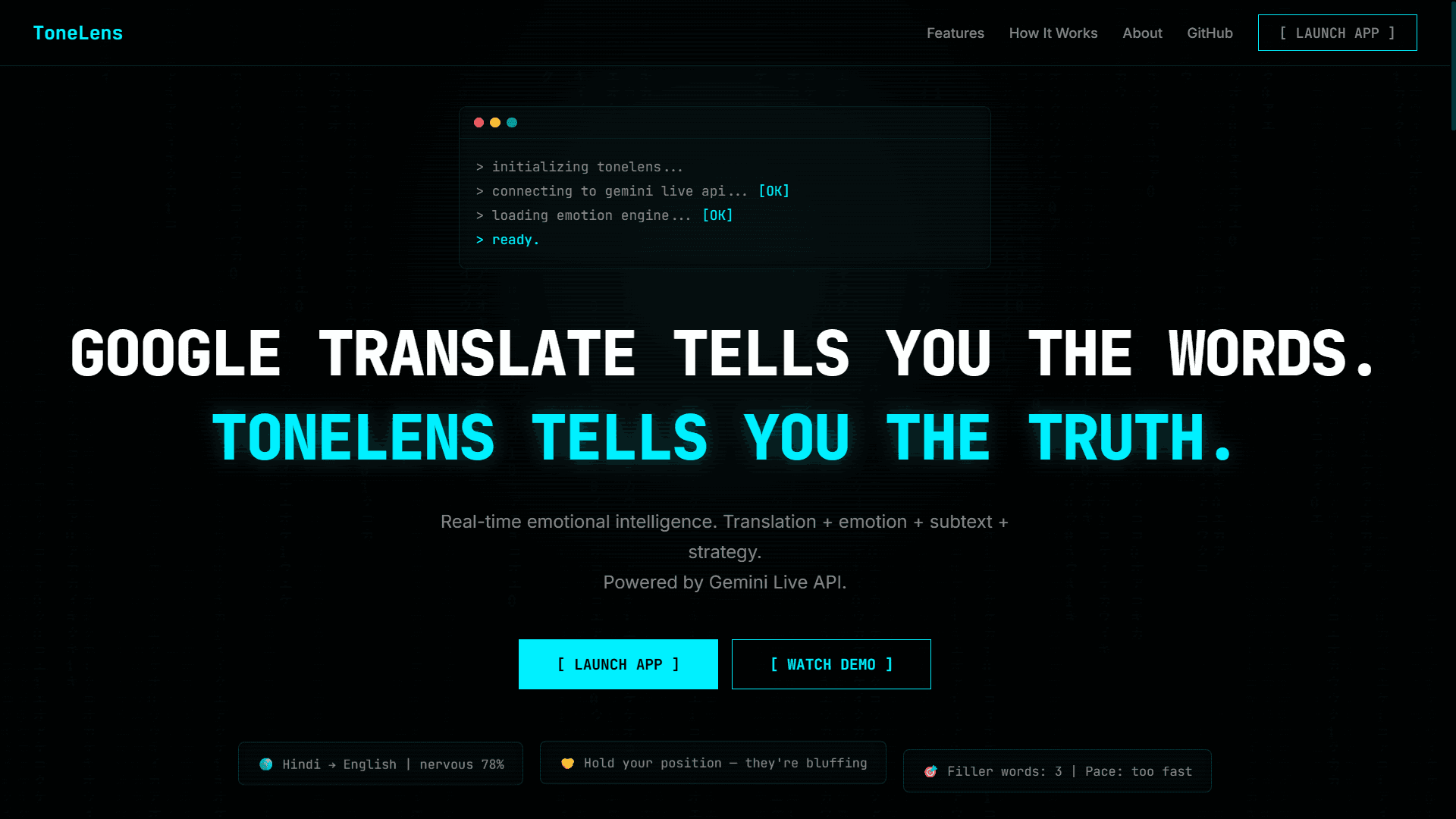
HOW I BUILT TONELENS IN 7 DAYS FOR THE GEMINI LIVE AGENT CHALLENGE
A behind-the-scenes look at building a real-time emotional intelligence agent using the Gemini Live API — from idea to submission in 7 days. Four modes, one multimodal pipeline, zero sleep.
The Idea
I've been in conversations where I said exactly the right words but completely the wrong way — and things fell apart. That stuck with me.
When I found out about the Gemini Live Agent Challenge 2026 and saw what the Gemini Live API could do with real-time audio, I immediately thought: what if an AI could coach you through emotional tone in the moment, not after the damage is done?
I'm 18, living in a college hostel, watching people around me lose arguments, negotiations, and friendships — not because they were wrong, but because of how they came across. That frustration became ToneLens.
Google Translate tells you the words. ToneLens tells you the truth.
The Stack
I had 7 days. I needed something that could handle simultaneous audio and video streaming with low latency and actual intelligence. Here's what I landed on:
- Gemini Live API (
gemini-2.5-flash-native-audio-latest) — core multimodal engine, receiving JPEG frames + raw PCM audio simultaneously over WebSocket - Vertex AI (
gemini-2.0-flash) — second-pass structured formatter that coerces freeform Gemini output into labeled lines the frontend can parse reliably - FastAPI + Uvicorn + WebSockets — backend bridge handling audio queuing, frame capture, and agent actions
- Google Cloud Firestore — session memory, meeting notes, exchange history
- Google Cloud Run + Docker — 2Gi RAM, 2 vCPU, deployed and live
- Web Audio API — 16kHz PCM base64 audio capture from the browser
- Vanilla HTML/CSS/JS + Chart.js — frontend (black and matrix-green aesthetic, because this is serious tooling, not a therapy app)
The architecture looked like this:
[CAMERA] ──┐
├──► [FASTAPI / CLOUD RUN] ──► [GEMINI LIVE API]
[MIC] ─────┘ │ │
│◄───────────────────────┘
│
├──► [VERTEX AI] (structured formatter)
├──► [FIRESTORE] (session memory)
├──► [agent.py] (cultural / emergency / notes / stress)
│
▼
[YOUR BROWSER]
Translation | Emotion | Subtext | Strategy
The 4 Modes
ToneLens isn't one thing. It's four distinct agents sharing the same multimodal pipeline:
🌍 Travel — Real-time translation with emotional context and cultural tips. If you're in a tense exchange in a foreign language, ToneLens doesn't just translate the words — it surfaces the subtext and cultural nuance behind them. There's also an emergency overlay with instant access to hospital, police, and Call 112.
📋 Meeting — Stress tracking, key decision capture, and automatic meeting note export. A live chart tracks tension levels across the conversation. When the meeting ends, you get a structured summary with decisions and action items pulled from Firestore.
🎤 Present — Filler word detection, pace analysis, and real-time delivery coaching. It catches every "um", "like", and "you know" as you speak and coaches you to slow down or pick up pace mid-sentence.
🤝 Negotiate — The one I'm most proud of. Power balance scoring, whisper coach, bluff detection, and momentum tracking mid-deal. During a mock salary negotiation roleplay while testing, it caught tension I hadn't consciously noticed myself. That was the moment I knew this was real.
The Hardest Part
Three things nearly broke me:
1. Latency on Cloud Run cold starts. The first few seconds of every session were eaten by cold start time. I had to build an audio queuing system in the backend that held incoming PCM chunks until the Gemini Live session was fully ready, then drained them cleanly — without dropping frames or desynchronizing the audio stream.
2. Freeform model output vs. structured UI. Gemini Live returns intelligent, conversational text. My frontend needed labeled lines it could parse reliably: EMOTION: frustrated (78%), SUBTEXT: they're stalling, POWER: 62 seller. Raw model output and production UI requirements are very different things. The second-pass Vertex AI formatter was one of the most important engineering decisions I made — it added a small latency cost but made the whole system stable.
3. WebSocket frame management under load. Keeping the WebSocket from dropping frames while simultaneously handling audio streaming, video capture, Firestore writes, and agent action triggers took a lot of careful async queue management in FastAPI. Most of this was debugged solo at 1AM with the Gemini API docs open in one tab and my deployed app breaking in another.
Demo & Results
ToneLens is live at tonelens-1095027648976.us-central1.run.app.
All four modes work end-to-end with the Gemini Live API in a single deployed app. The whole thing — idea, architecture, build, and deployment — happened in 7 days, mostly in late nights after 4PM classes.
Building a real multimodal pipeline — browser camera and mic capture, live WebSocket transport, Gemini Live audio+video response, structured second-pass reasoning, and Firestore session memory — as an 18-year-old first-year student, solo, in 7 days, feels like a real proof of concept.
What I Learned
The Gemini Live API is not just a voice interface. It's genuinely capable of processing simultaneous audio and video streams and holding emotional context across a multi-turn conversation in a way that feels like it understands subtext — not just words.
Raw model output ≠ production UI. This seems obvious in hindsight, but the gap between "the model understands this" and "the frontend can render this reliably" is massive. The formatter layer was the bridge.
Scope is a trap. I came in thinking I'd build a simple tone detector. I left having built something that felt closer to a real multimodal agent. That happened because I kept asking "what would make this actually useful in a real conversation?" — and let that question drive the scope, not a feature list.
What's Next
The immediate next step is replacing keyword-triggered agent actions with actual Gemini Live function-calling once the model config supports it — which will make the agent behavior much more dynamic and context-aware.
I also want to add cross-session memory so ToneLens can track emotional patterns over time and give longitudinal feedback on how your communication style is evolving.
Long term, I think there's a real product here for conflict resolution training, sales coaching, and language learning. After the hackathon, I want to test that with real users.
If you want to try it or follow what comes next:
- 🚀 Launch ToneLens
- 💻 GitHub
Built for Gemini Live Agent Challenge 2026 · #GeminiLiveAgentChallenge